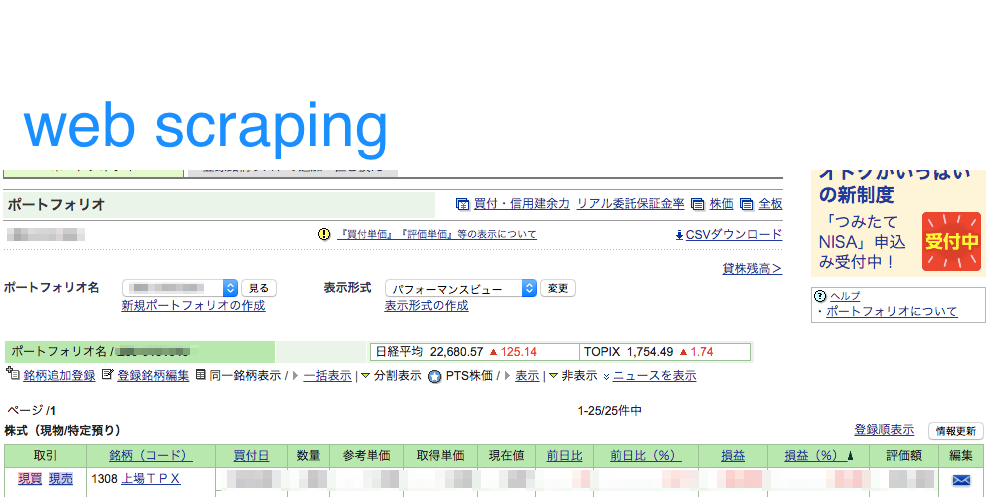
SBI証券のポートフォリオをPythonのseleniumを利用して、webスクレイピングで実装しました。毎回ログインして記録していくのは大変ですが、スクレイピングをすれば一気に取得できます。
AWSのLambdaに乗せて、dailyでデータを取得して、可視化、というのも面白そうです。
SBI証券の自分のポートフォリオの情報をスクレイピング
スクレイピングの手順はログインして、ポートフォリオ画面に遷移して、今のデータをダウンロードするだけです。
この画面の情報をスクレイピングします。
Pythonで実装
ライブラリのインストール
import os
import time
import datetime
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoupSBI証券へのログイン
SBI証券に接続する部分です。SBI証券のサイトを開き、アカウントとパスワードを入力してログインするところまでです。
def connect_sbi(ACCOUNT, PASSWORD, name):
options = Options()
# ヘッドレスモード(chromeを表示させないモード)
options.add_argument('--headless')
driver = webdriver.Chrome(options=options, executable_path='get_sbi/chromedriver')
# SBI証券のトップ画面を開く
driver.get('https://www.sbisec.co.jp/ETGate')
# ユーザーIDとパスワード
input_user_id = driver.find_element_by_name('user_id')
input_user_id.send_keys(ACCOUNT)
input_user_password = driver.find_element_by_name('user_password')
input_user_password.send_keys(PASSWORD)
# ログインボタンをクリック
driver.find_element_by_name('ACT_login').click()
return driverポートフォリオ画面からスクレイピング
スクレイピング部分です。
ポートフォリオ画面に遷移し、データを取得します。私は株式、投資信託、NISAをやっているので、それぞれのテーブル毎にデータを取得し、その後に結合しています。
株式しかやっていない方は、テーブルの位置がずれると思うので、その場合は適宜、削ってみてください。こんなに必要ありません。
soup.find_allの引数の探し方がかっこ悪いのでどうにかしたいのですが、id属性がないために、このようにしています。
def get_ja_data(driver):
# 遷移するまで待つ
time.sleep(4)
# ポートフォリオの画面に遷移
driver.find_element_by_xpath('//*[@id="link02M"]/ul/li[1]/a/img').click()
# 文字コードをUTF-8に変換
html = driver.page_source.encode('utf-8')
# BeautifulSoupでパース
soup = BeautifulSoup(html, "html.parser")
# 株式
table_data = soup.find_all("table", bgcolor="#9fbf99",, cellpadding="4", cellspacing="1", width="100%")
# 株式(現物/特定預り)
df_stock_specific = pd.read_html(str(table_data), header=0)[0]
df_stock_specific = format_data(df_stock_specific, '株式(現物/特定預り)', '上場TPX')
# 株式(現物/NISA預り)
df_stock_fund_nisa = pd.read_html(str(table_data), header=0)[1]
df_stock_fund_nisa = format_data(df_stock_fund_nisa, '株式(現物/NISA預り)', '上場TPX')
# 投資信託(金額/特定預り)
df_fund_specific = pd.read_html(str(table_data), header=0)[2]
df_fund_specific = format_data(df_fund_specific, '投資信託(金額/特定預り)', '')
# 投資信託(金額/NISA預り)
df_fund_nisa = pd.read_html(str(table_data), header=0)[3]
df_fund_nisa = format_data(df_fund_nisa, '投資信託(金額/NISA預り)', '')
# 投資信託(金額/つみたてNISA預り)
df_fund_nisa_tsumitate = pd.read_html(str(table_data), header=0)[4]
df_fund_nisa_tsumitate = format_data(df_fund_nisa_tsumitate, '投資信託(金額/つみたてNISA預り)', '')
# 結合
df_ja_result = pd.concat([df_stock_specific, df_stock_fund_nisa, df_fund_specific, df_fund_nisa, df_fund_nisa_tsumitate])
df_ja_result['date'] = datetime.date.today()
return df_ja_result取得データのフォーマット
データのフォーマットです。評価額と損益と損益(%)のみ抽出しています。
def format_data(df_data, category, fund):
# 必要な列のみ抽出
df_data = df_data.loc[:, ['評価額', '損益', '損益(%)']]
df_data['カテゴリー'] = category
if fund != '':
df_data['ファンド名'] = fund
return df_datacsvによる出力
データ出力の部分です。
def export_data(df_result, name):
df_result.to_csv(name + '_result_{0:%Y%m%d}.txt'.format(datetime.date.today()))メイン関数
ここから呼び出しています。
if __name__ == '__main__':
ACCOUNT = 'hatosuke'
PASSWORD = 'PASSWORD'
name = 'NAMAE'
driver = connect_sbi(ACCOUNT, PASSWORD, name)
df_ja_result = get_ja_data(driver)
export_data(df_ja_result, name)
# ブラウザーを閉じる
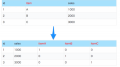
driver.quit() スクレイピング結果
ぼかしすぎていますが、このようにcsv形式でデータを取得することができます。日々データを取得して遷移をみるといったこともできそうですね。
まとめ
Pythonでブラウザを操作できるseleniumを利用したSBI証券のデータ取得をやりました。SBI証券で毎月の資産をチェックしている方は、これを使えば便利です。
また、同じような手法を用いればSBI証券だけでなく、他のサイトの情報も取得できるようにできそうです。

コメント