
https://aws.amazon.com/jp/blogs/big-data/developing-aws-glue-etl-jobs-locally-using-a-container/で AWS Glue環境をDockerで構築する方法が掲載していたのでやってみました。AWS Glueの開発は画面からだとデバックが遅すぎるので、ローカルにAWS Glue環境を立てると、ローカルで開発することができます。
Docker imageをpull
Dockerに公式のimageが上がっているのでpullします。
docker pull amazon/aws-glue-libs:glue_libs_1.0.0_image_01コンテナの起動
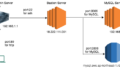
imageからコンテナを起動させます。オプションの意味をすぐ忘れてしまうので、記載しておきます。
docker run -itd -p 8888:8888 -p 4040:4040 -v C:\Users\hatosuke\.aws:/root/.aws:rw --name glue_jupyter amazon/aws-glue-libs:glue_libs_1.0.0_image_01 /home/jupyter/jupyter_start.sh- -itd : i(interactive)は標準入力、t(tty)は擬似ターミナル、d(detach)はバックグラウンドで実行
- -p 8888:8888 : 8888はJupyterのデフォルトポート、左の外部のポート8080と、右のコンテナ内部のポート8080を接続
- -p 4040:4040 : 4040はSparkUIのデフォルトポート、左の外部のポート4040と、右のコンテナ内部のポート4040を接続
- -v C:\Users\hatosuke\.aws:/root/.aws:rw : ホストのフォルダC:\Users\hatosuke\.awsを、コンテナの/root/.awsにマウント、rwなのでDocker側から読み書きができる
- –name glue_jupyter : glue_jupyterというコンテナ名を付与
- amazon/aws-glue-libs:glue_libs_1.0.0_image_01 : docker image
- /home/jupyter/jupyter_start.sh : コンテナで Jupyter notebookを起動する
コンテナ内への入り方
コンテナへの入り方です。
docker exec -it glue_jupyter bash
root@20bd9d08e432:/#- exec : 実行中のコンテナ内で、新しいコマンドを実行
- -it : i(interactive)は標準入力、t(tty)は擬似ターミナル
- glue_jupyter : バックグラウンドで起動しているglue_jupyter
- bash : bashセッションの開始
プロキシの設定
会社ではプロキシが通っているので、コンテナ内でプロキシ設定して、通信できるようにします。
root@20bd9d08e432:/# export HTTP_PROXY=http://hatosuke:passwd@jp.hato:1234
root@20bd9d08e432:/# export HTTPS_PROXY=http://hatosuke:passwd@jp.hato:1234s3へのアクセス
プロキシ経由でネットに接続できるようにしたので、s3にアクセスが可能になります。
root@20bd9d08e432:/# aws s3 ls
2020-04-03 05:10:43 testJupyter、PySparkが実行できる
http://localhost:8888でJupyterを開けるようになり、また下記のようにPySparkをCLIで操作できるようになります。
root@20bd9d08e432:/# /home/spark-2.4.3-bin-spark-2.4.3-bin-hadoop2.8/bin/pyspark
Python 3.6.10 (default, Jun 9 2020, 18:36:16)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
21/02/22 11:33:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Python version 3.6.10 (default, Jun 9 2020 18:36:16)
SparkSession available as 'spark'.
>>>一番ハマったのはプロキシ設定の部分です。プロキシ設定を見つける前は、なぜかs3がアクセスできない状態が続いていて、ふと気づいて解決できました。

コメント