
インバウンドの訪日外国人動向を利用して、時系列分析をしてみました。
JTB総合研究所のサイトにインバウンドの訪日外国人動向ということで、1996年1月から2018年3月までの月別の訪日外国人数のデータがあったので、これを利用しての分析です。
観測データはそのままだと、たまたま季節変動によるプラスによる影響で上がっているように見えるだけで、実際のトレンドは下がっていたりします。この問題を解決するために、観測データを「トレンド + 季節変動 + 残差」に分けるモデルがあります。
今回はインバウンドの訪日外国人の数を「トレンド + 季節変動 + 残差」に分割してみて、本当に訪日外国人が増えているのか、そして季節による変動はあるのかをチェックしてみます。
インプットデータの加工
データはエクセル形式なので、解析に必要な人数だけのデータにしたcsvにします。
csvでは日時は入れずに、数だけ抜き取っています。分析するときに年月をセットするのでこれで問題ありません。
Rで分析
Rを利用して時系列分析しました。
ファイルの読み込み¶
df = read.table(file = "~/Desktop/analysis/R/time/input/inbound.csv", header = T)
モデルの作成¶
# ts : 時系列オブジェクトを生成する
# start = c(1996,1) : 最初の観測値の時間。1996年1月がスタート
# frequency = 12 : 時間単位毎の観測値数。今回は月ごとのデータなので、12回で1年となる
xt = ts(as.numeric(df$number), start = c(1996,1), frequency = 12)
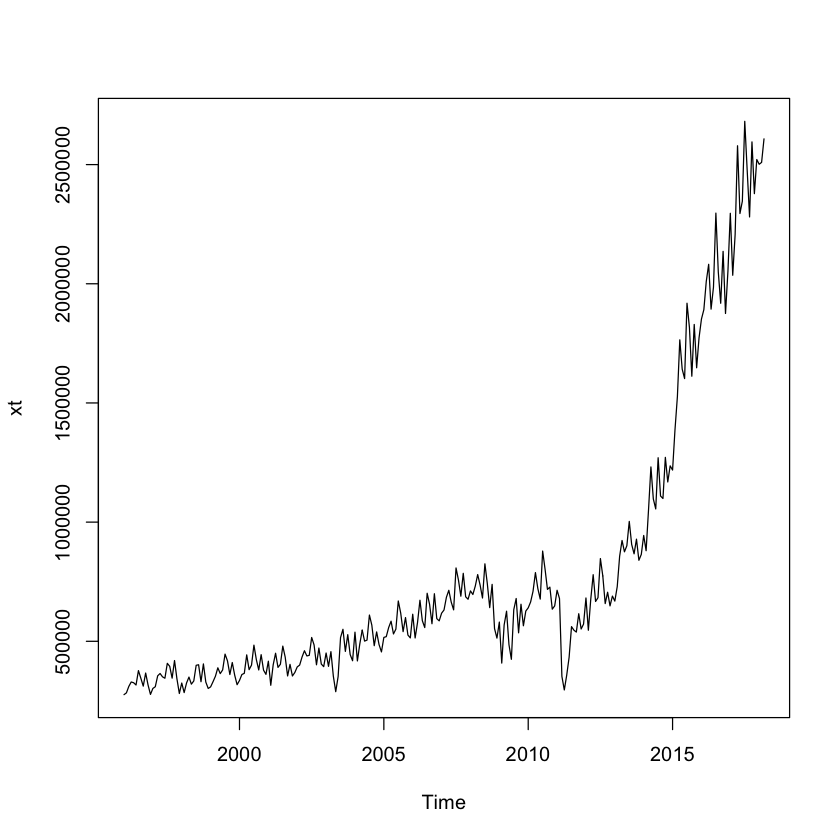
プロット¶
plot(xt)
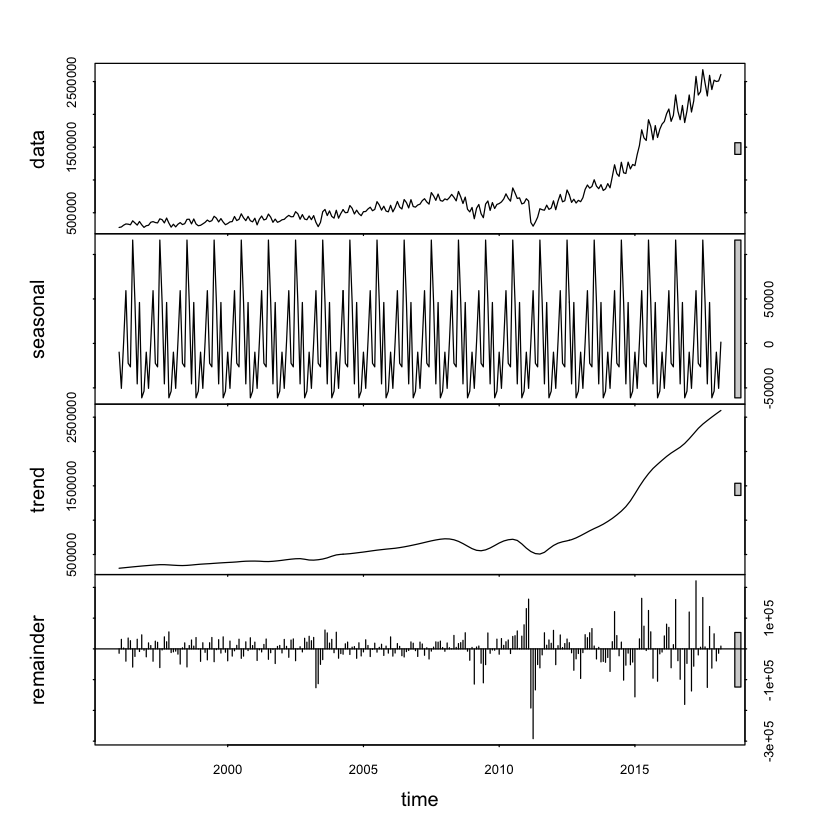
# stl : 時系列データを、トレンド、周期変動、残差に分解する関数
xt.stl<-stl(xt, s.window="periodic")
plot(xt.stl)
# 季節調整した部分を分離したい場合は、トレンドと残差を足す
plot(xt.stl$time.series[,2]+xt.stl$time.series[,3])
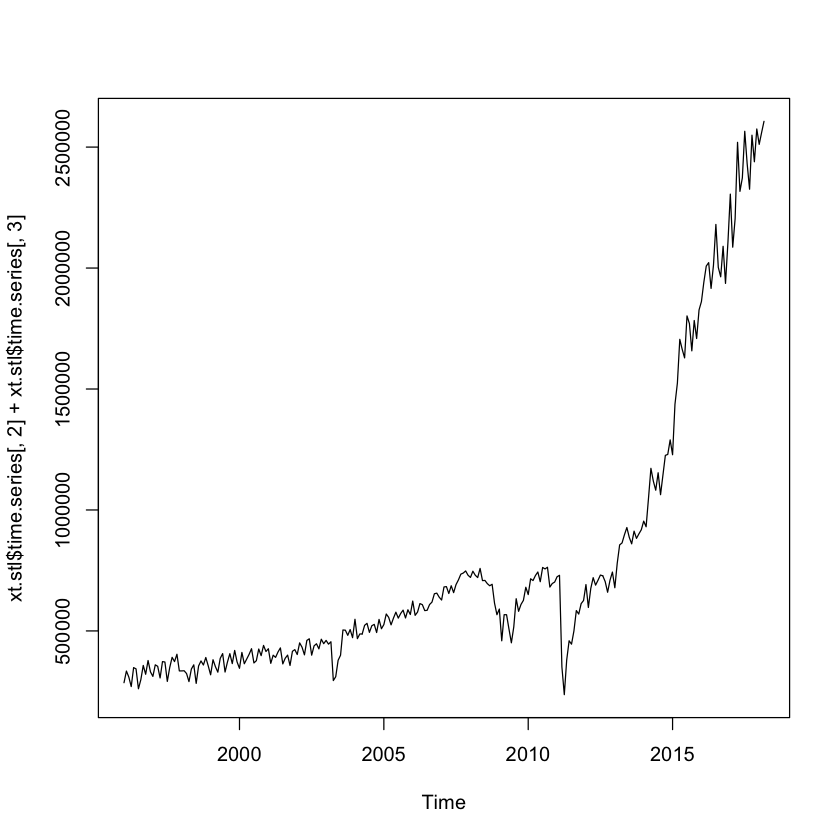
ファイルで出力¶
# csvファイルで出力
write.csv(xt.stl$time.series[,1], file = 'seasonal.csv', row.names = F)
write.csv(xt.stl$time.series[,2], file = 'trend.csv', row.names = F)
write.csv(xt.stl$time.series[,3], file = 'remainder.csv', row.names = F)
考察
トレンド
csv出力した「trend.csv」をTableau(無料で使えるBI)で視覚化してソート。
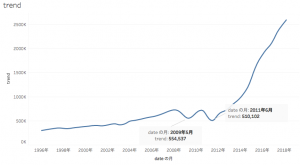
2009年5月の凹みは2008年9月のリーマンショックの影響で、2011年の凹みは2011年3月の地震の影響でしょうか。
地震の前からトレンドは少し下降気味だったので、この理由は知りたいところです。
季節変動
csv出力した「seasonal.csv」をTableauで視覚化してソート。
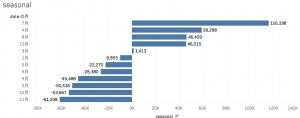
トップ3とワースト3を見てみましょう。
トップ3
| 順位 | 月 | 人数 |
| 1位 | 7月 | +116,198 |
| 2位 | 4月 | +59,298 |
| 3位 | 8月 | +46,459 |
ワースト3
| 順位 | 月 | 人数 |
| 1位 | 11月 | -61,208 |
| 2位 | 12月 | -53,667 |
| 3位 | 2月 | -50,516 |
旅行者は暑い夏が好きだということが見て取れます。2位の4月の倍の差をつけて、7月が1番でした。8月が3位なのは、日本人の夏休みと重なるのでどこに行っても混んでいるから避ける、とかですかね。
4月が2位なのは桜といったら日本というイメージがついてきている結果でしょうか。ただ桜の開花は短い上に時期がブレることが多いので、訪日しても思うように見れない人も多そうです。
まとめ
このように時系列分析自体はts関数を利用するだけでできてしまいます。この後の予測ではforecastやFacebookのprophetで行えます。
それは次の機会にします。
参考


コメント